Race conditions are often a cause for concern in software development. Where traffic is managed at scale — whether that be in APIs, databases, or event-driven platforms — platforms must robustly handle concurrent requests with conflicting intent. This is pertinent to serverless platforms where the underlying resources scale automatically to handle more traffic, meaning the risk of race conditions may increase when more data is processed in parallel.
Kraken’s commercial Flex APIs leverage serverless technology on AWS: relying on services like API Gateway and Lambda to fulfil energy supply and demand across the world. Most of these APIs use DynamoDB - a managed NoSQL offering - for data persistence, but there is one API that relies on an RDS Aurora MySQL database cluster. This cluster consists of one primary node for read / write traffic as well as replica instances for read traffic only.
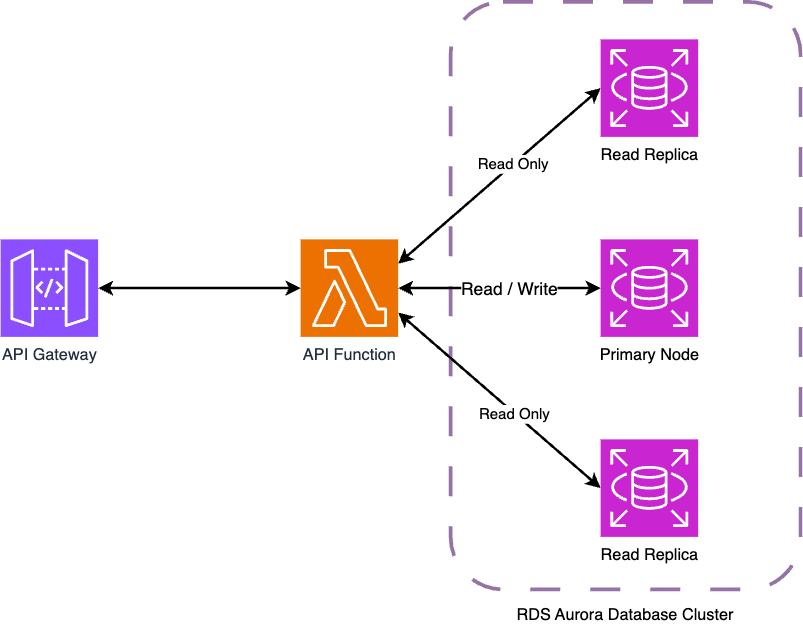
As more commercial assets join the Kraken platform, more requests are processed simultaneously that read and write to the cluster. This means there is a greater risk of conflicting write requests that the database must robustly handle. This blog post outlines an example race condition that may arise between parallel write requests, before sharing a couple of options to remediate the problem between the API and the database. Whilst some of what is shared here applies to all RDBMS options, much of this content is specific to MySQL and a storage engine implementation called InnoDB.
Example race condition
The database stores time series data. In its simplest form, each row includes the following attributes:
device_ididentifying the commercial asset on the platform.beginISO timestamp indicating when data starts to take effect.endISO timestamp indicating when data stops taking effect.
For each device_id, there cannot be any two rows in the database with overlapping intervals between begin and end.
Below are a couple of example rows, both relating to device ID 100. One row applies from 12pm until 3pm on January 1st, whilst the other applies from 6pm to 9pm on the same day. Therefore the device has no overlapping row entries.
| device_id | begin | end |
|---|---|---|
| 100 | 2024-01-01T12:00:00.000Z | 2024-01-01T15:00:00.000Z |
| 100 | 2024-01-01T18:00:00.000Z | 2024-01-01T21:00:00.000Z |
A typical write request to the Flex API contains an array. Each array element includes a device ID as well as begin and end timestamps. An example of the request body is provided below.
[
{
"begin": "2024-01-01T19:00:00.000Z",
"end": "2024-01-01T20:00:00.000Z",
"deviceId": "100"
},
{
"begin": "2024-01-01T22:00:00.000Z",
"end": "2024-01-02T23:00:00.000Z",
"deviceId": "101"
}
]
For each array element, one row must be inserted into the database if no overlapping database entry already exists. Therefore the request flow is as follows:
- find the earliest
begin(x) and latestend(y) from the array - read all existing rows for all device IDs that overlap between
xandy - for each device ID, verify no existing overlapping rows are read
- insert new row(s) for the requested device ID, begin, and end values
Translating these steps into SQL operations, one SELECT query is executed to fetch existing rows before running one INSERT query. Overlap checks between new and existing data are managed by the API.
Suppose two requests come in for device ID 100. One of those requests spans 3pm and 5pm, whilst the other intends to write data between 4pm and 6pm. Each request reads its respective time range with an overlap between the hours of 4pm and 5pm before they separately write new data for that shared interval. If the two requests arrive in quick succession, the below sequence of steps may occur.
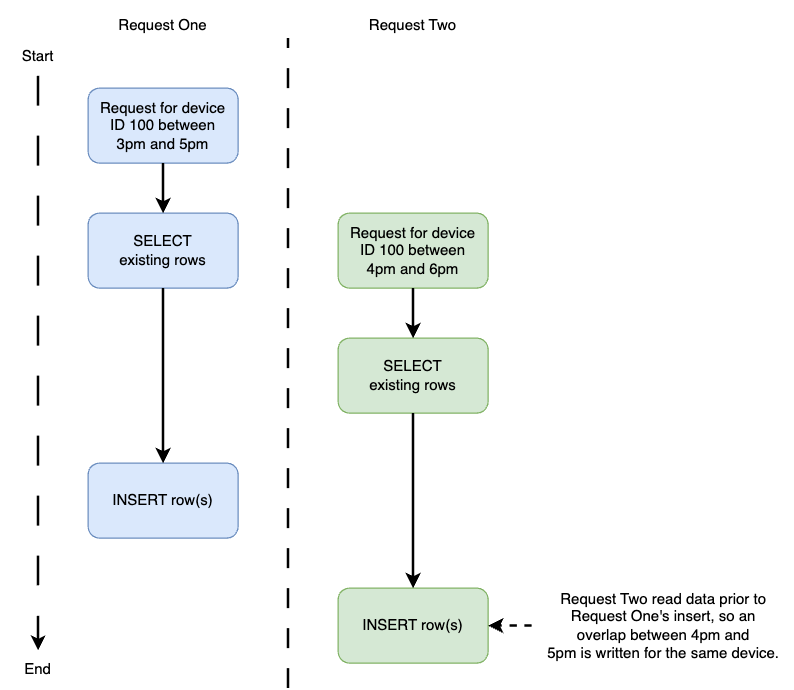
In this scenario, the API failed to detect an overlap, so both requests were successfully written to the database. This leaves the data in a conflicting state: device ID 100 has two rows for the interval between 4pm and 5pm. There are a couple approaches worth sharing that can prevent this conflict from arising.
Optimistic locking
One option is a technique called “optimistic locking”, which is agnostic of the underlying RDBMS. This pattern enforces conditions on insert queries before any rows are created by extending a standard INSERT query into an INSERT INTO SELECT. Consider the below example which takes parameters :deviceId, :begin, and :end to be written to attributes device_id, begin, and end respectively:
INSERT INTO my_table (device_id, begin, end)
SELECT :deviceId, :begin, :end
FROM my_table
WHERE 0 = (
SELECT COUNT(*)
FROM my_table
WHERE device_id = :deviceId
AND begin < :end
AND end > :begin
)
LIMIT 1;
The query works as follows:
- The nested
SELECTquery counts how many rows havedevice_idequal to:deviceIdand an overlap between the given:beginand:endparameters. - If the count is zero then there are no overlaps:
- The outer
SELECTreturns the parameter values:deviceId,:begin, and:end. Note that no existing data is returned from the table, only the parameter values. - The
INSERTclause writes:deviceId,:begin, and:endinto attributesdevice_id,begin, andend.
- The outer
- On the other hand, if the count is non-zero then an overlap is detected:
- The
SELECTreturnsNULLand theINSERTis skipped.
- The
- A
LIMITof 1 is set so the parameter values are only inserted once when there is a count of zero. Otherwise the number of inserts matches the row count for tablemy_table.
Given all of this logic is managed in a single INSERT INTO SELECT query, the race condition is mitigated: there’s no delay between reading then writing data. However, this example only applies if one row is to be inserted into the database.
If many rows must be inserted then there are several sets of :deviceId, :begin, and :end values. One option would be to extend the WHERE criteria of the nested SELECT statement for each parameter value set, but this would yield considerable complexity in the SQL query, especially if the query must handle a variable number of entries for insertion.
Alternatively each value set may execute its own INSERT INTO SELECT query within a database transaction. This means all changes across queries can be committed or rolled back at once. The below steps would be required:
- Begin a transaction with
BEGINorSTART TRANSACTION. - For every device ID, execute an
INSERT INTO SELECTquery, which returns an insert count. - If any query returns insert count
0then rollback all changes withROLLBACK: an optimistic lock failed. - If all queries return insert count
1then commit all changes withCOMMIT: all optimistic locks succeeded.
This is a viable path forward. However, the API is responsible then for executing more queries: one INSERT per device ID rather than one for everything. This means there is a greater increase in latency, which means a greater risk of request conflicts. To mitigate conflicts whenever an INSERT count is zero, retries would be required after short waiting periods, further adding to latency. The expected performance degradation is not great for customers.
Pessimistic locking
Instead of running conditional checks in the INSERT query, there is the option of locking down the database itself within a transaction to avoid conflicts known as pessimistic locking. This can be applied to entire tables or individual rows of a table. Table locks would affect entire tables, which is heavily restrictive on other transactions, so this option was reserved as a last resort.
Row locks on the other hand take two forms: shared and exclusive. In both forms, behaviour varies depending on the chosen transaction isolation level. MySQL with the InnoDB storage engine defaults to a level called REPEATABLE_READ, which differs from other RDBMS options like PostgreSQL. When a lock is applied, it takes effect until the transaction either commits or rolls back all of its changes.
A shared lock under REPEATABLE_READ locks parts of the database so no transactions can write to those areas. Given the API must insert new rows, a shared lock was not fit for purpose. On the other hand, an exclusive lock under REPEATABLE_READ locks parts of the database so only the transaction enforcing the lock can read and write to those places. All other connections must wait for this transaction to commit or rollback its changes before they can proceed. The scope of an exclusive row lock depends on query criteria.
Examples of exclusive row locking
Consider the example database rows from before.
| device_id | begin | end |
|---|---|---|
| 100 | 2024-01-01T12:00:00Z | 2024-01-01T15:00:00Z |
| 100 | 2024-01-01T18:00:00Z | 2024-01-01T21:00:00Z |
Suppose there is a unique index for attributes device_id, begin, and end, so no two rows share the same set of values. To read all rows for device ID 100 that begin at 6pm and end at 9pm, the below query can be executed. Clause FOR UPDATE at the bottom applies the lock.
SELECT *
FROM my_table
WHERE device_id = 1
AND begin = '2024-01-01T18:00:00Z'
AND end = '2024-01-01T21:00:00Z'
FOR UPDATE;
Since the query leverages the unique index on device_id, begin, and end with strict equality checks, it only locks parts of the database index that match the query conditions. Suppose instead a query is executed for all data related to device ID 100 on 1st January 2024. There are two matching rows in this time range.
SELECT *
FROM my_table
WHERE device_id = 1
AND begin < '2024-01-02T00:00:00.000Z' AND end > '2024-01-01T00:00:00.000Z'
FOR UPDATE;
Again, this query uses the unique index, but this time inequality checks apply. In such cases, the index range is locked. This means matching rows as well as gaps between the rows in the index are locked. Suppose now, whilst the lock remains in place, another transaction executes the below query from 12pm on January 1st until 12pm on January 2nd.
SELECT *
FROM my_table
WHERE device_id = 1
AND begin < '2024-01-02T12:00:00.000Z' AND end > '2024-01-01T12:00:00.000Z'
FOR UPDATE;
Since this query shares the same device ID as the first, whilst overlapping the other transaction’s query range by 12 hours, it will have to wait until the first transaction has committed or rolled back all of its changes before results are returned. The hold on the second transaction until the first one has finished guarantees that the second transaction will read all the changes from the first.
Occasionally with pessimistic locking two transactions may reach deadlock. Deadlocks occur where two transactions try to lock the same parts of the database in parallel. This is not observed often, even when the database operates under load, but when they do occur a retry is valuable after a short waiting period.
Like optimistic locking, increases in latency apply with exclusive locks, but the risk is expected to be smaller for a couple reasons. Firstly, transactions wait the minimum required duration to avoid a conflict, whereas optimistic locking waits arbitrarily between retry attempts. In the latter case, a retry interval could be set longer than is required. Furthermore, it is possible to create all new rows for a request using a standard INSERT query - there’s no need for conditional criteria proposed through optimistic locking which could grow quite complex - so pessimistic locking is easier for developers to maintain.
Conclusion
Pessimistic locking at a row-level actively runs in production for the database today, alleviating race condition concerns shared in this blog post. Since going live, no notable latency increase was observed. Deadlocks only emerged on occasion during load tests, all of which were handled automatically with internal API retries.
Implementing this solution required further investment upfront from developers to gain a greater understanding of MySQL and the InnoDB storage engine. However, the benefits are that latency remains at acceptable levels for customers and the development team maintains simpler queries in the API.
For further reading on MySQL, InnoDB, and locking strategies, please refer to High Performance MySQL, 4th Edition by Silvia Botros and Jeremy Tinley as well as the MySQL Reference Manual.
Would you like to help us build a better, greener and fairer future?
We're hiring smart people who are passionate about our mission.
- How we ship in 2026
- Static typing Python at scale - Our journey with mypy and Django
- Django, Kubernetes Health Checks and Continuous Delivery
- Working with async Django: lessons learned
- Making a major RabbitMQ version upgrade without breaking Celery ETA tasks
- Electrifying and flexing low-carbon domestic heating in the home
- Building an AI copilot to make on-call less painful
- Building the largest electric vehicle smart-charging virtual power plant in the world
- How we ship over 100 versions a day to over 25 environments in more than 10 countries
- Estimating cost per dbt model in Databricks
- Automating secrets management with 1Password Connect
- Understanding how mypy follows imports
- Optimizing AWS streams consumer performance
- Sharing power updates using Amazon EventBridge Pipes
- Using formatters and linters to manage a large codebase
- Our pull request conventions
- Patterns of flakey Python tests
- Integrating Asana and GitHub
- Durable database transactions in Django
- Python interfaces a la Golang
- Beware changing the "related name" of a Django model field
- Our in-house coding conventions
- Recommended Django project structure
- Using a custom Sentry client
- Improving accessibility at Octopus Energy
- Django, ELB health checks and continuous delivery
- Organising styles for a React/Django hybrid
- Testing for missing migrations in Django
- Hello world, would you like to join us?